
Python se ha convertido en uno de los lenguajes de programación más populares para el análisis de datos, y con razón. Su amplia gama de bibliotecas y herramientas de análisis hace que sea una elección poderosa para investigadores y profesionales que desean extraer información valiosa de sus datos. En este artículo, exploraremos las capacidades de Python en el análisis de datos a través de un emocionante caso de estudio en el campo de la política monetaria.
El Caso de Estudio: Análisis de la Política Monetaria de la Reserva Federal
En este caso de estudio, hemos utilizado Python para analizar una serie de datos que abordan la política monetaria de la Reserva Federal de Estados Unidos. Hemos realizado una serie de pruebas estadísticas esenciales para evaluar la calidad y la robustez de un modelo de regresión lineal robusta (RLM) que relaciona la tasa de fondos federales con las tasas de crecimiento de la productividad (Deltapr) y la inflación (Deltacpi), además de una variable dummy para representar un evento relevante asociada a la invención del Quantitative Easing (dummyqe).
Las Maravillas de Python en Acción
Hemos utilizado Python para llevar a cabo una variedad de pruebas y análisis, demostrando las capacidades de este lenguaje:
- Prueba de Cointegración: Comenzamos evaluando la relación de cointegración entre las variables utilizando Python. Esta prueba es esencial para determinar si existe una relación a largo plazo entre las variables y si pueden utilizarse en una regresión.
- Prueba de Multicolinealidad: Utilizamos Python para evaluar la multicolinealidad entre las variables independientes. Esta prueba es vital para garantizar que nuestras variables explicativas no estén altamente correlacionadas, lo que podría afectar la interpretación del modelo.
- Prueba de Autocorrelación: Hicimos uso de Python para examinar la autocorrelación de los residuos del modelo. Esto nos permite identificar cualquier patrón en los residuos y asegurarnos de que no haya estructuras de dependencia temporal no capturadas en el modelo.
- Prueba de Normalidad: Empleamos Python para verificar la normalidad de los residuos. La normalidad de los residuos es una suposición importante de la regresión lineal, y esta prueba nos ayuda a confirmar su validez.
- Prueba de Homocedasticidad: Además de las pruebas mencionadas, también exploramos la homocedasticidad de los residuos de nuestro modelo en Python. La homocedasticidad se refiere a la igualdad de la varianza de los residuos en todos los niveles de las variables independientes. Al verificar la homocedasticidad, aseguramos que los errores de nuestro modelo sean constantes en todas las condiciones, lo que es esencial para la validez de las inferencias y predicciones del modelo. En este caso, Python nuevamente demostró su utilidad al proporcionarnos las herramientas necesarias para evaluar la homocedasticidad y garantizar la calidad del modelo.
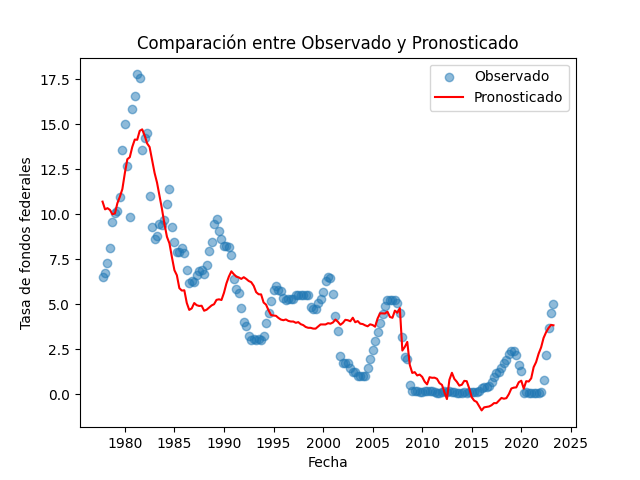
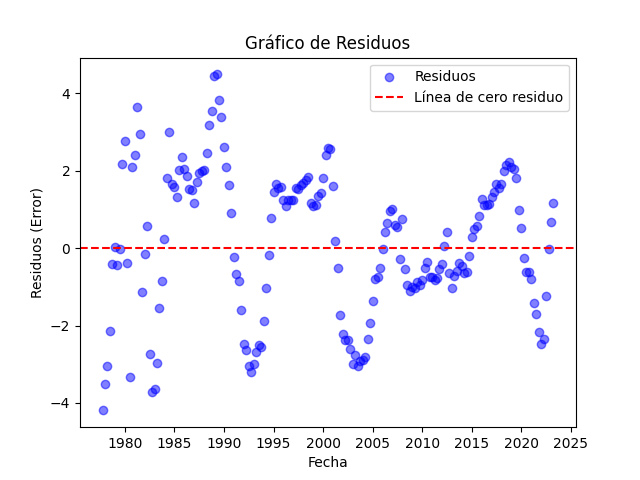
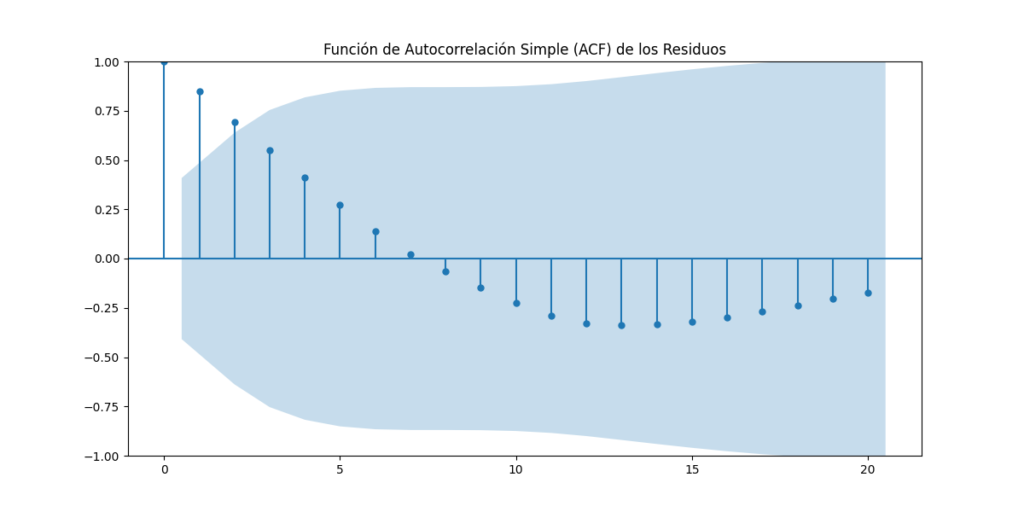
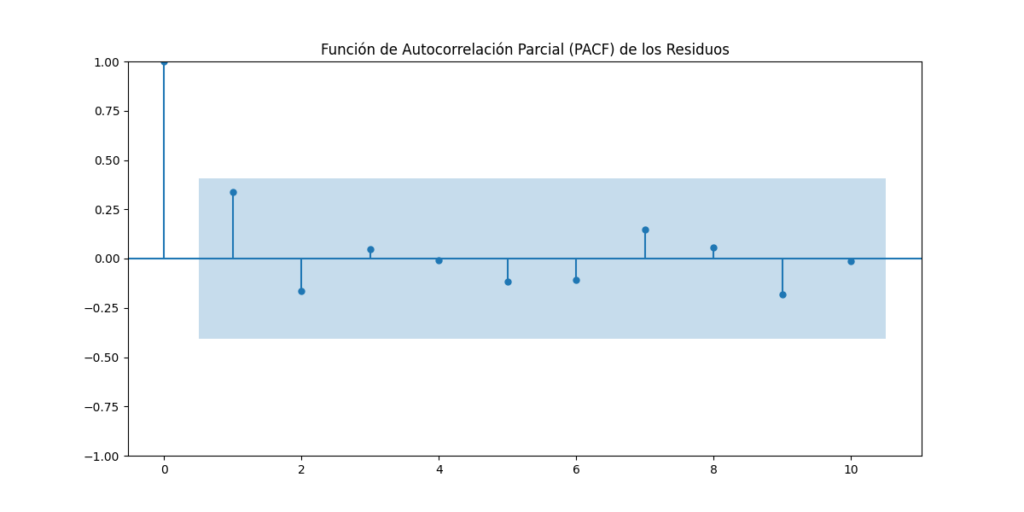



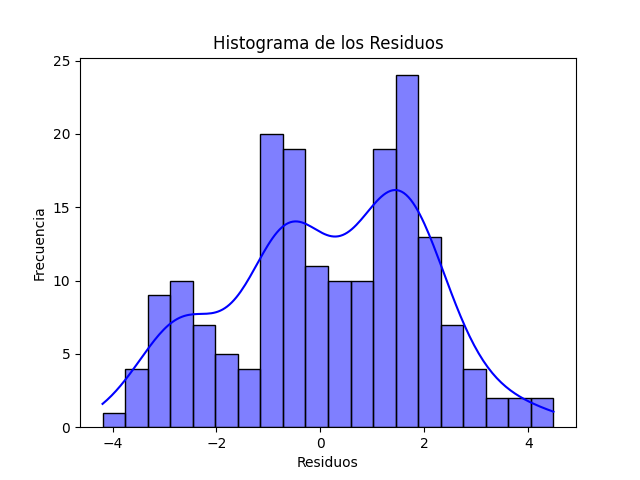
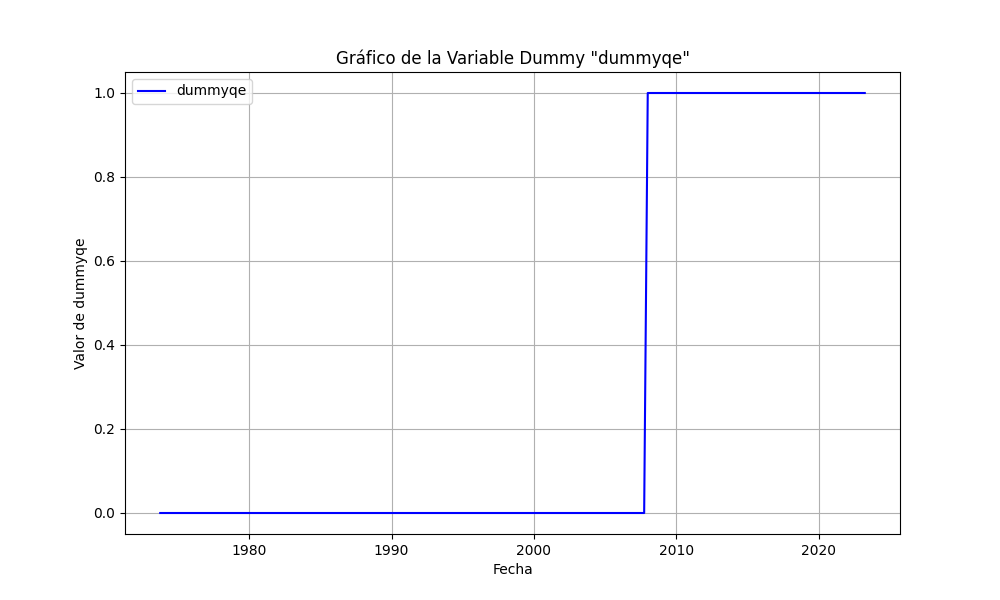
Resultados del Análisis
Luego de realizar estas pruebas, procedimos a ajustar un modelo de regresión lineal robusta (RLM) en Python. Los resultados son impresionantes:
Robust linear Model Regression Results
==============================================================================
Dep. Variable: fedfundsrate No. Observations: 183
Model: RLM Df Residuals: 180
Method: IRLS Df Model: 2
Norm: HuberT
Scale Est.: mad
Cov Type: H1
Date: Wed, 11 Oct 2023
Time: 22:05:51
No. Iterations: 17
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Deltapr 23.8637 10.801 2.209 0.027 2.695 45.033
Deltacpi 135.0490 4.329 31.196 0.000 126.564 143.534
dummyqe -2.4010 0.283 -8.493 0.000 -2.955 -1.847
==============================================================================
R-squared: 0.8705Los resultados son prometedores: hemos identificado una fuerte relación entre las tasas de crecimiento de la productividad, la inflación y la política monetaria. El valor de R-squared (R2) de 0.8705 indica que nuestro modelo explica el 87.05% de la variabilidad en la tasa de fondos federales. Además, los coeficientes estimados proporcionan información valiosa sobre la relación entre las variables (en este otro artículo enfoco los resultados y hallazgos desde la perspectiva económica).
Conclusión
Este caso de estudio es solo un ejemplo de cómo Python puede ser utilizado para el análisis de datos. Con las pruebas exitosas de cointegración, multicolinealidad, autocorrelación, y normalidad, hemos demostrado la versatilidad y potencia de Python en el análisis de datos. Python es una herramienta esencial para aquellos que desean explorar y entender sus datos a fondo, extrayendo información valiosa que puede respaldar la toma de decisiones informadas. ¡Las maravillas de Python están al alcance de todos aquellos que buscan aventurarse en el emocionante mundo del análisis de datos!
¡Descubre más sobre Python y el análisis de datos en nuestro blog!
¡Ya en Amazon!
¡No pierdas esta oportunidad única y limitada para obtener un 50% de descuento en el precio original del programa de cursos asociado a 'CAMINO A LA RIQUEZA'! Utiliza el código 'caminoalariqueza' al momento de la compra y asegura tu cupón de descuento exclusivo para lectores del libro. Esta oferta de descuento estará disponible de manera intermitente en el tiempo, por lo que es mejor aprovecharlo ahora mismo. Adquiere las herramientas necesarias y emprende tu camino hacia la riqueza financiera antes de que sea demasiado tarde. ¡No te quedes fuera de esta oportunidad imperdible!
¡Emprende tu camino hacia la riqueza ahora!